DataFusion
DataFusion is an extensible query execution framework, written in Rust, that uses Apache Arrow as its in-memory format.
DataFusion supports both an SQL and a DataFrame API for building logical query plans as well as a query optimizer and execution engine capable of parallel execution against partitioned data sources (CSV and Parquet) using threads.
DataFusion also supports distributed query execution via the Ballista (Arrow) crate.
It doesn’t have its own storage format. That makes it ideal for running SQL queries on files in CSV, Parquet, JSON, Arrow, and Avro formats, whether they’re stored locally, in cloud storage, or on HTTP servers, similar to DuckDB.
# Use Cases
Data Fusion is a single node, not distributed (why it was donated to Apache Arrow as an in-memory technology?). If you want to distribute it, you can use Ray for Python as Andy Grove said in Andy Grove, or Ballista (Arrow).
According to Denny, it’s so fast, that you almost do not need distribution, but you can easily get it with Ray. Also as e.g. delta-rs is built in Rust, it’s so tiny, that he can use a Lambda function with it, which makes it extremely powerful. Imagine the difference to the Java JVM version, which comes with so much overhead and one reason Spark is so complex I guess.
From the GitHub Repo:
DataFusion can be used without modification as an embedded SQL engine or can be customized and used as a foundation for building new systems. Here are some examples of systems built using DataFusion:
- Specialized Analytical Database systems such as CeresDB and more general spark like systems such a Ballista (Arrow)
- New query language engines such as prql-query(PRQL) and accelerators such as VegaFusion
- Research platform for new Database Systems, such as Flock
- SQL support to another library, such as dask sql
- Streaming data platforms such as Synnada
- Tools for reading / sorting / transcoding Parquet, CSV, AVRO, and JSON files such as qv
- A faster Spark runtime replacement (blaze-rs)
By using DataFusion, the projects are freed to focus on their specific features, and avoid reimplementing general (but still necessary) features such as an expression representation, standard optimizations, execution plans, file format support, etc.
# TableProviders
Integrate datafusion in dlt or similar, so we could do select * from slack.users.

Docs for TableProvider:
Custom Table Provider — Apache DataFusion documentation
Custom Table Provider
Like other areas of DataFusion, you extend DataFusion’s functionality by implementing a trait. The TableProvider and associated traits, have methods that allow you to implement a custom table provider, i.e. use DataFusion’s other functionality with your custom data source.
This section will also touch on how to have DataFusion use the new TableProvider implementation.
Table Provider and Scan
The scan method on the TableProvider is likely its most important. It returns an ExecutionPlan that DataFusion will use to read the actual data during execution of the query.
# Why DataFusion?
- High Performance: Leveraging Rust and Arrow’s memory model, DataFusion achieves very high performance
- Easy to Connect: Being part of the Apache Arrow ecosystem (Arrow, Apache Parquet and Flight), DataFusion works well with the rest of the big data ecosystem
- Easy to Embed: Allowing extension at almost any point in its design, DataFusion can be tailored for your specific usecase
- High Quality: Extensively tested, both by itself and with the rest of the Arrow ecosystem, DataFusion can be used as the foundation for production systems.
# Comparisons with other projects
Here is a comparison with similar projects that may help understand when DataFusion might be be suitable and unsuitable for your needs:
- DuckDB is an open source, in process analytic database. Like DataFusion, it supports very fast execution, both from its custom file format and directly from parquet files. Unlike DataFusion, it is written in C/C++ and it is primarily used directly by users as a serverless database and query system rather than as a library for building such database systems.
- Polars: Polars is one of the fastest DataFrame libraries at the time of writing. Like DataFusion, it is also written in Rust and uses the Apache Arrow memory model, but unlike DataFusion it does not provide SQL nor as many extension points.
- Facebook Velox is an execution engine. Like DataFusion, Velox aims to provide a reusable foundation for building database-like systems. Unlike DataFusion, it is written in C/C++ and does not include a SQL frontend or planning /optimization framework.
- DataBend is a complete database system. Like DataFusion it is also written in Rust and utilizes the Apache Arrow memory model, but unlike DataFusion it targets end-users rather than developers of other database systems.
# DuckDB vs. Datafusion
- Comparing it to DuckDB: Duckdb Vs. Datafusion - by Matt Martin - Matt’s Substack
# Who is using it?
- Ballista (Arrow)
- ROAPI: Build directly on apache arrow and DataFusion.
- Cube with Cube Store
- InfluxDB
- GlareDB,
- Lance
More from know-users
- Here are some active projects using DataFusion:
- Arroyo Distributed stream processing engine in Rust
- CnosDB Open Source Distributed Time Series Database
- Dask
- Exon Analysis toolkit for life-science applications
- delta-rs Native Rust implementation of Delta Lake (delta lake rust)
- GreptimeDB Open Source & Cloud Native Distributed Time Series Database
- HoraeDB Distributed Time-Series Database
- Kamu Planet-scale streaming data pipeline
- LakeSoul Open source LakeHouse framework with native IO in Rust.
- Parseable Log storage and observability platform
- qv Quickly view your data
- bdt Boring Data Tool
- Restate Easily build resilient applications using distributed durable async/await
- Seafowl CDN-friendly analytical database
- Synnada Streaming-first framework for data products
- VegaFusion Server-side acceleration for the Vega visualization grammar
- ZincObserve Distributed cloud native observability platform
- Here are some less active projects that used DataFusion:
- Blaze: Spark accelerator with DataFusion at its core
- Cloudfuse Buzz
- datafusion-tui Text UI for DataFusion
- Flock
- Tensorbase
# Apple and DataFusion
# Extensions
# dbt (ADBC)
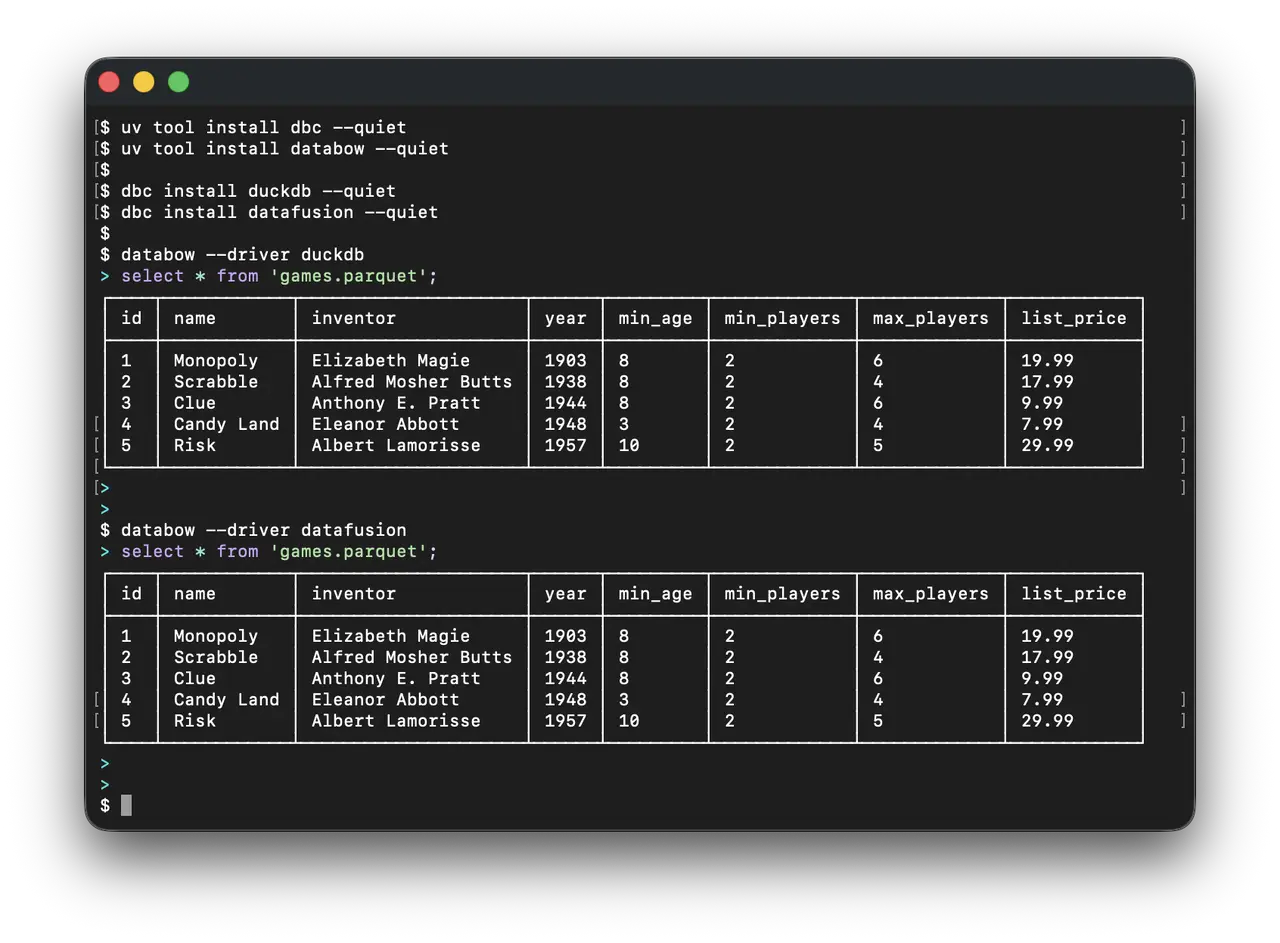
Since 2026-06-09 there’s a dbc connector, Ian shares:
This ADBC driver embeds DataFusion and makes it easy to use from 10+ languages through ADBC’s simple interface. The SQL syntax matches what you’d use in the DataFusion CLI. The driver takes no connection arguments; you control it entirely through the SQL you run.
Install with:
|
|
# Further Reads
- Why Startups Are Betting Everything on Apache DataFusion - The New Stack
- Duck Hunt: moving Bauplan from DuckDB to DataFusion: LinkedIn by Duck Hunt
Origin:
References: ROAPI Apache Arrow Rust