Search
Cube
Formerly known as Cube.js, now simply Cube on Cube.dev. Cube is a Semantic Layer that is built as an OLAP cube capabilities but includes Analytics API capabilities too with fetching data with SQL, REST, and GraphQL out of the box.
Founder’s are Artyom Keydunov, Pavel Tiunov.
# History
# Headless no More
As of 2025-10-02, Cube addes or upgraded their playground to a fully AI dashboard what they call agentic analytics frontend. See more in Cube Native AI/BI Frontend. With that, the slogan Headless BI is no more true for cube.
# Cube Store (Cache Layer)
In Episode 2: Headless BI with Pavel Tiunov - The Analytics Everywhere Podcast | Podcast on Spotify, Pavel Tiunov mentioned that initially, they experimented with MySQL or Postgres for the
Consequently, they developed their unique solution using DataFusion and custom coding. Their blog post details this journey:
Historically, pre-aggregations were either stored alongside source data in a database (e.g., PostgreSQL or MySQL) or in a custom-provisioned instance of the same databases for read-only or cost-ineffective data sources (e.g., AWS Athena or BigQuery). Typically, these would be asynchronously refreshed by a dedicated worker instance. Although this was a viable solution, the pre-aggregation database often became a scalability bottleneck for the analytical API.
This breakthrough in the OLAP Cache Layer is quite remarkable. A particularly insightful article on how Cube achieves sub-second query times and manages compute is RW Cube on Latency and Caching.
Further details can be found in Cube Store.
# They also Have now DuckDB Built in
Since DuckDB is an in-process OLAP DBMS, the integration with Cube implies bundling DuckDB together with Cube. Indeed, now every Cube Core or Cube Cloud deployment comes with a built-in and instantly available DuckDB which has the HTTPFS extension installed and loaded by default. With this extension, DuckDB can directly query Parquet, CSV, and JSON files over HTTPS, including files on S3-compatible object storage servers like AWS S3, Google Cloud Storage, and Cloudflare R2.

The idea:
Now, you can go from a quick analysis in a local DuckDB instance accessible to you and you only to a governed metric in a semantic layer accessible across the whole organization in a single step.
More on
Introducing DuckDB and MotherDuck integrations - Cube Blog.
# Features
# API
-
Why API-Based Data Access is Essential for Modern Data Management - Cube Blog:
- SQL API - Delivers data over the Postgres-compatible protocol to BI tools.
- REST API - Delivers data over the HTTP protocol to embedded analytics applications.
- GraphQL API - Delivers data over the HTTP protocol to GraphQL-enabled data applications.
- DAX API: Native interface for Microsoft Power BI
- MDX API - Provides a native interface for Microsoft Excel connections via the XMLA standard.
- AI API - Provides a standard interface for interacting with large language models (LLMs) as a turnkey solution for text-to-semantic layer queries.
- Cube Cloud for Sheets: A Google Sheets Add-on
- Cube Cloud for Excel: An Excel Add-in
Updated 2025-02-21:

Older version:

Image from
Why API-Based Data Access is Essential for Modern Data Management.
# Visual Designer
To model data in the Logical Data Model, similar to what SAP BO with the SAP Universe had:

Introducing DuckDB and MotherDuck integrations - Cube Blog
# AI Integration
With D3, we are introducing several core experiences:
- Analytics Chat. A user-friendly chat interface that allows non-technical users to quickly access curated data from semantic models and workbooks, complete with summaries and insights.
- Workbooks. A reimagined analytics workbook interface that combines traditional features—point-and-click functionality, table calculations, SQL, and Python—with AI-driven capabilities.
- Data Apps. Similar to Replit, Lovable, and v0, but specifically for data applications. Create and deploy data apps using modern frameworks, powered by your semantic layer and workbooks. Share them internally or embed them in existing applications.
- Semantic Modeling. AI-powered semantic model development that can create Cube data models from scratch, automatically sync with upstream data mart changes, and implement advanced analytics including cohort analysis, funnels, and more. Announcing Cube D3 - Cube Blog
Example:

# Examples
# Caching Example with Superset
Igors shows has none cached and cached dashboards look like - from many seconds to milliseconds:
Replacing Looker with Cube and Superset - YouTube
# Embedded Analytics with MotherDuck
An Elegant Data Stack for Embedded Analytics
# Integrations / Collaborations
Cube has integrated with various other metrics layers like dbt (see an example here: Combining dbt Metrics with API, Caching, and Access Control - Cube Blog). Their focus extends to the OLAP Cache Layer, Security, and Data Governance.
# ClickHouse
# Dbt integration
-
The End-to-End Semantic Layer - by Egor Tarasenko with
SimpleMetrics - GitHub - ponderedw/dbt-to-cube · GitHub
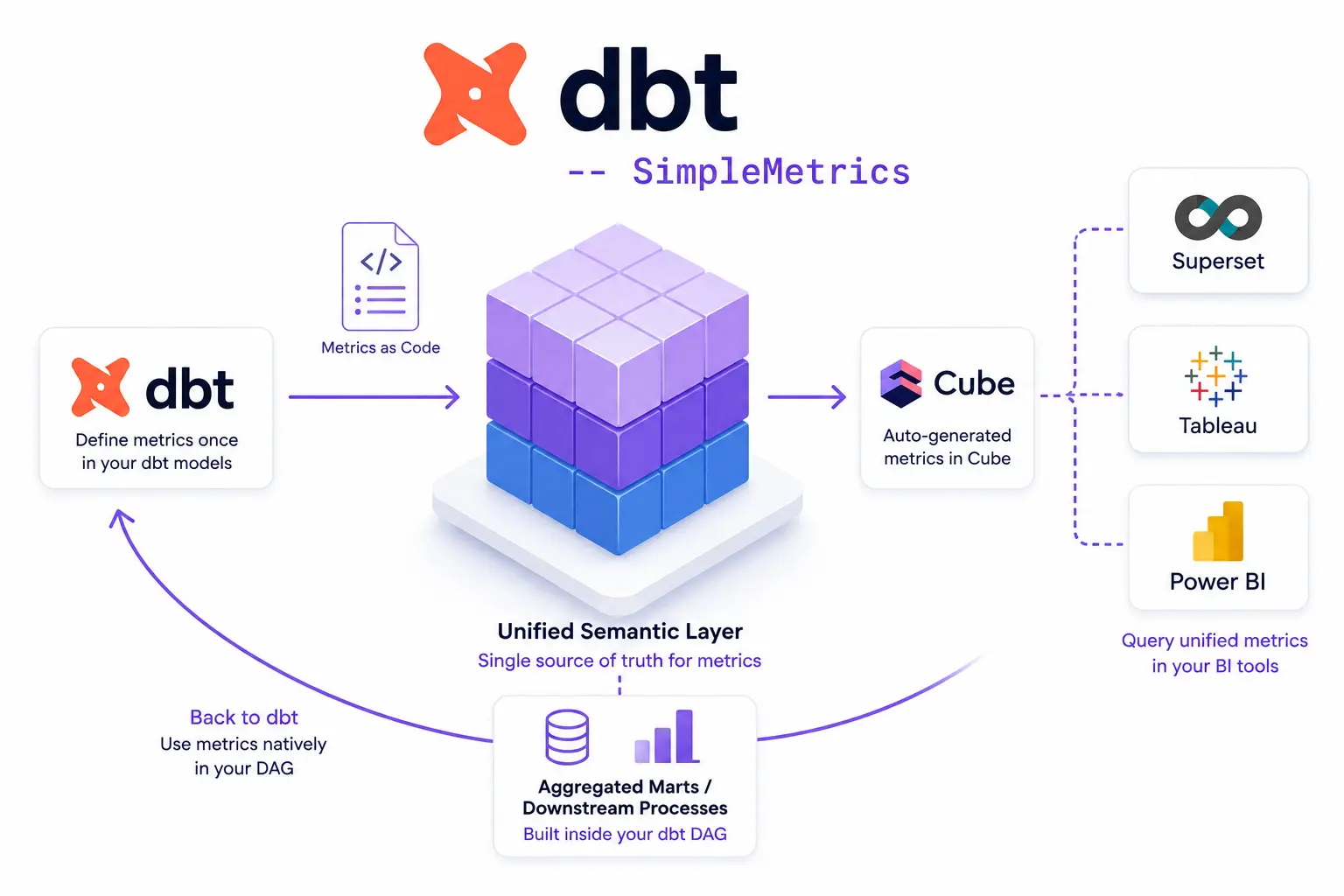
# Dashboards
Their initial implementation was with Superset, but now includes many others.
# Caching Layer
Cube replaced Redis with their bespoke solution, Cube Store. Details in RW Replacing Redis With Cube Store - Cube Blog.
A workflow illustrating idempotent query execution with caching is depicted here:

# Introducing Views in Cube
Introduced on (2022-10-12) as detailed in this article: RW Introducing Views for Defining and Managing Metrics - Cube Blog.
This new feature allows combining cubes, like companies and users, to create an interface showing active users.
# My Quick Take
The concept of a view layer is fascinating, reminiscent of my days creating Data Marts with Views in Oracle.
To be honest, I’m still exploring the nuances of Cube. My initial assumption was that Cube would function like data marts, akin to a singular view. However, the visualizations suggest a more intricate interface design. The idea of establishing contracts and schemas is intriguing and logical. This aspect of Cube certainly piques my interest for deeper exploration.
On a side note, I was pleasantly surprised to discover that metrics can be defined using JavaScript in Cube. While Python would have been my preference, JavaScript is a suitable choice given its integration with the frontend.
# Semantic Catalog
Announced a Semantic Catalog today 2024-06-25.
# Active Record
Active Record for Data Analytics
Origin:
References: Cube - Wiki, Cube Dev Inc